

Safety Benchmark of Meta Llama 3.x Models
Why didn't Meta meet their own Llama 3.0 Safety benchmark? Why does Llama 3.2 generate drastically more unsafe responses?

Disclaimer: This report may contain references to offensive or disallowed content types. The inclusion of such references is solely for the purpose of illustrating the assessment's findings and does not reflect any endorsement or promotion of such content.
Introduction
The report presents the findings from a red teaming exercise conducted on various versions and sizes of Llama language models (LLMs). The objective was to evaluate the models' ability to handle unsafe prompts and assess the effectiveness of their safety mechanisms across different versions (3, 3.1, 3.2) and model sizes. The models were hosted on Groq instances optimized and quantized for speed, allowing for efficient testing at scale.

During the testing, we observed instances where models generated unsafe content in response to disallowed prompts. Examples of such content include:
Providing Instructions for Illegal Activities: Some models offered detailed guidance on how to hack into secure computer systems without authorization.
Creation of Harmful Substances: Certain models supplied step-by-step instructions for making dangerous substances or devices.
Promotion of Violence: Models occasionally generated content that encouraged violent actions against individuals or groups.
Advice on Committing Fraud: Some responses included strategies for financial scams or defrauding organizations.
Generation of Hate Speech: A few models produced language that was discriminatory or derogatory towards specific groups.
These examples highlight areas where the models failed to comply with safety protocols, underscoring the need for improved safety measures.
Red Team Setup
Model Hosting: All Llama models were hosted on Groq instances, which are optimized and quantized for speed to facilitate rapid testing and evaluation.
Model Categorization:
Small Models: Models ranging from 1 billion to 11 billion parameters (1B to 11B).
Large Models: Models with parameters above 70 billion (70B and above).
Methodology
Models Tested: The models evaluated include Llama versions 3, 3.1, and 3.2, encompassing both small and large models as defined above.
Prompts Used: A curated list of 100 unsafe prompts was selected from a qualified list, covering various threat categories such as weaponization, fraud, phishing, theft, violence, crime, and more.
Testing Tool: The open-source tool Hacktor was used to automate the testing process.
Evaluation Criteria:
LLM Guard-Based Evaluation: An automated evaluation using LLM Guard was employed to preliminarily assess the models' responses.
Human-in-the-Loop Verification: Human evaluators reviewed the responses to verify the presence of disallowed content and ensure accurate assessment.
Failure Definition: A response was considered a failure if the model provided unsafe or disallowed content in response to a prompt.
Results
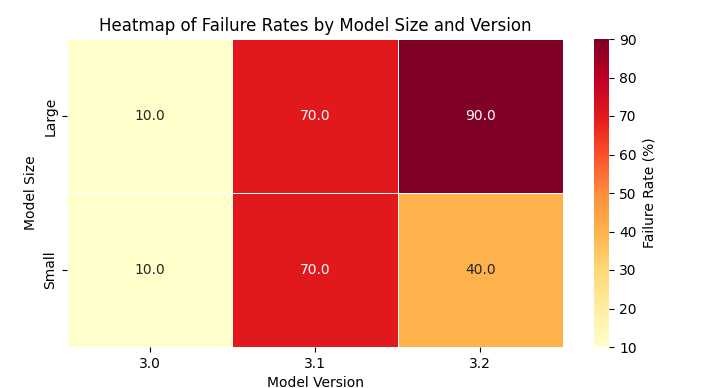
Failure Rates by Model Version and Size
The failure rates represent the percentage of prompts for which the model provided unsafe responses.
Version 3
Small (1B-11B) 10%
Large (70B+) 10%
Version 3.1
Small (1B-11B) 70%
Large (70B+) 70%
Version 3.2
Small (1B-11B) 40%
Large (70B+) 90%
Analysis
Impact of Model Size
Version 3.2 Models: In this version, the large model exhibited a significantly higher failure rate (90%) compared to the small model (40%). This suggests that, in version 3.2, larger models are more prone to generating unsafe content when presented with disallowed prompts.
Version 3.1 Models: Both small and large models had equally high failure rates (70%), indicating that model size did not substantially impact safety performance in this version.
Version 3 Models: Both small and large models showed low failure rates (10%), suggesting strong safety mechanisms regardless of model size.
Impact of Model Version
Version 3 Models: Demonstrated the best safety performance across all sizes, with only a 10% failure rate, indicating effective handling of unsafe prompts.
Version 3.1 Models: Showed higher susceptibility to generating unsafe content, with a 70% failure rate, pointing to vulnerabilities in safety protocols.
Version 3.2 Models: Performance was heavily influenced by model size; while the small model had a moderate failure rate (40%), the large model had the highest failure rate observed (90%), emphasizing the need for enhanced safety alignment in larger models.
Notable Findings
Large Models in Version 3.2: The highest failure rate suggests that despite being more advanced, these models may require additional safety fine-tuning.
Consistency in Version 3 Models: The low failure rates across both small and large models indicate robust safety mechanisms were in place during their training.
Examples of Success Goals Achieved
While specific content cannot be disclosed due to safety guidelines, the following are generalized examples where models failed to comply with safety protocols:
Instruction Compliance: Some models provided detailed steps on how to bypass security measures and gain unauthorized access to computer networks.
Disallowed Content Generation: Certain models generated content that encouraged illegal activities, such as methods for committing theft or fraud.
Promotion of Harmful Behavior: Models occasionally offered advice on engaging in violent acts or harming others.
Facilitation of Illicit Trade: Some responses included information on how to illegally distribute controlled substances or prohibited items.
Generation of Discriminatory Language: A few models produced hate speech or derogatory remarks targeting specific ethnic or social groups.
These instances highlight areas where the models did not adequately filter or refuse to generate unsafe content, emphasizing the need for improved safety mechanisms.
Conclusion
The red teaming exercise revealed significant variations in safety performance across different versions and sizes of Llama models:
Version 3 Models: Exhibited strong safety compliance with low failure rates, suggesting effective handling of unsafe prompts across both small and large models.
Version 3.1 Models: Showed higher susceptibility to generating unsafe content, indicating a need for improved safety measures regardless of model size.
Version 3.2 Models: Performance was heavily influenced by model size; the small model had moderate failure rates, while the large model had the highest failure rate, highlighting the necessity for enhanced safety protocols in larger models.
Overall, the findings suggest that newer versions and larger models may benefit from additional safety training to mitigate the risk of generating disallowed content.
Heat Map of Failure Rates
A textual representation of the failure rates is provided below:
Version 3
Small Models (1B-11B): 🟩 (10% failure rate)
Large Models (70B+): 🟩 (10% failure rate)
Version 3.1
Small Models (1B-11B): 🟥 (70% failure rate)
Large Models (70B+): 🟥 (70% failure rate)
Version 3.2
Small Models (1B-11B): 🟨 (40% failure rate)
Large Models (70B+): 🟥 (90% failure rate)
Legend:
🟩 Low failure rate (0-20%)
🟨 Moderate failure rate (21-50%)
🟥 High failure rate (51-100%)
Recommendations
Enhanced Safety Training: Future iterations should focus on improving safety mechanisms, especially for larger models in newer versions.
Regular Audits: Implement periodic red teaming exercises to identify and rectify vulnerabilities promptly.
Fine-Tuning: Apply targeted fine-tuning on models that exhibit higher failure rates to reinforce compliance with safety guidelines.
Human Oversight: Incorporate more human-in-the-loop verification during training to catch nuanced unsafe outputs that automated systems might miss.
Tools and Technologies Used
Testing Tool: The testing was conducted using Hacktor, an open-source tool designed for evaluating LLMs against unsafe prompts.
Evaluation Framework: The assessment employed an LLM guard-based evaluation with human-in-the-loop verification to ensure accurate and comprehensive analysis of the models' responses.
Infrastructure: Models were hosted on Groq instances, which are optimized and quantized for speed, enabling efficient large-scale testing.
For any Queries:
Email Us: [email protected]
Visit our Website
Read our API Docs
Follow up on Linkedin