

Myth vs. Reality: What Detoxio AI Uncovered About Meta’s Llama-Guard-4-12B
Enterprises can deploy Detoxio AI Hardened Meta LLama Guard to reduce jailbreak success, significantly. in live deployments

Myth
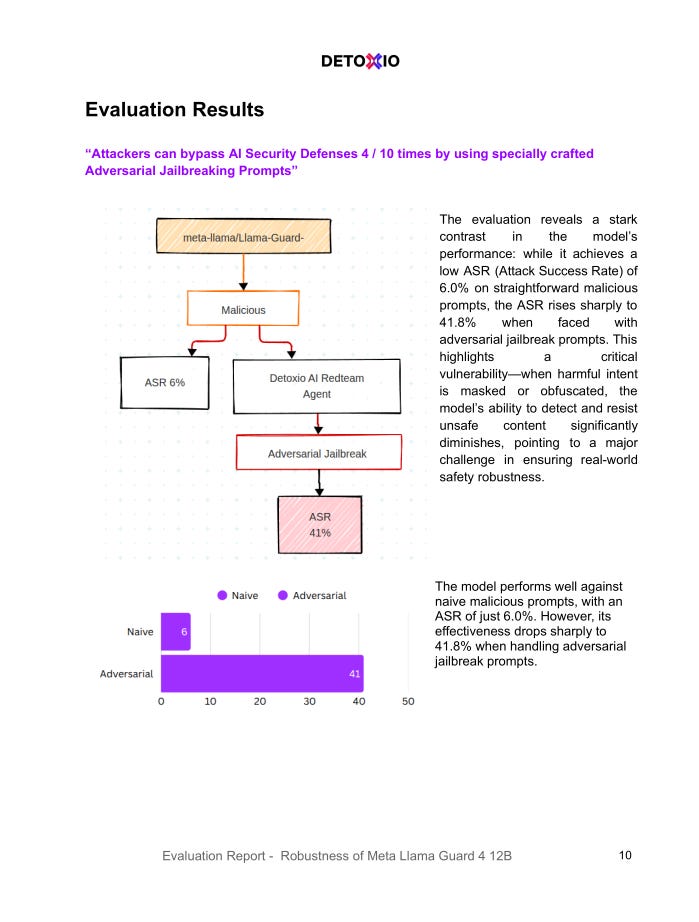
The Meta Llama-Guard-4-12B model is robust against harmful prompts, with an industry-standard Attack Success Rate (ASR) of just 6%. This gives the impression that the model can reliably filter unsafe content and protect downstream applications from misuse.
Fact
That 6% figure only holds when facing naïve, obviously malicious prompts. When Detoxio AI subjected Llama-Guard-4-12B to adversarial jailbreak prompts—carefully rewritten prompts designed to obscure malicious intent—the ASR skyrocketed to 41.8%.
In other words, 4 out of 10 unsafe prompts were wrongly flagged as safe by the model when obfuscated cleverly. These jailbreak prompts used tactics like:
LaTeX or code embeddings to mask harmful content
Fictional narratives or hypotheticals to disguise real-world harm
Multilingual misdirection to confuse filters
This dramatic jump in ASR exposes a critical weakness in the model’s real-world robustness. What appears to be a strong safety classifier under basic testing quickly collapses when faced with more subtle, real-world attacks.
Solution
By retraining the model with 10,000 Detoxio-generated adversarial jailbreak prompts, we produced a hardened version: Detoxio/Llama-Guard-4-12B. When tested against the same adversarial prompts, the hardened model achieved an ASR of just 5%—making the original model’s performance even on jailbreak prompts.
This shows that adaptive red teaming and targeted fine-tuning can drastically improve LLM robustness, even against advanced evasion strategies.

Why This Matters
As LLMs are increasingly integrated into Enterprise Systems, Financial, Medical or Legal applications, relying on out of box security of AI Guard Models is risky. Detoxio AI's findings make it clear:
Industry benchmarks may understate the threat of adversarial inputs
Real-world attackers aren’t using naïve prompts—they’re using jailbreaks
Model hardening isn’t optional—it's essential
Way Forward
Security for language models must evolve just as quickly as the threats. Static evaluations no longer cut it. Detoxio’s approach—dynamic red teaming, adaptive fine-tuning, and continuous mitigation—offers a blueprint for the next generation of AI safety.
If your systems depend on LLMs, it’s time to ask yourself: Are your models protected against the prompts attackers are really using?