

Distilled Deepseek Models
Safety Evaluation Report

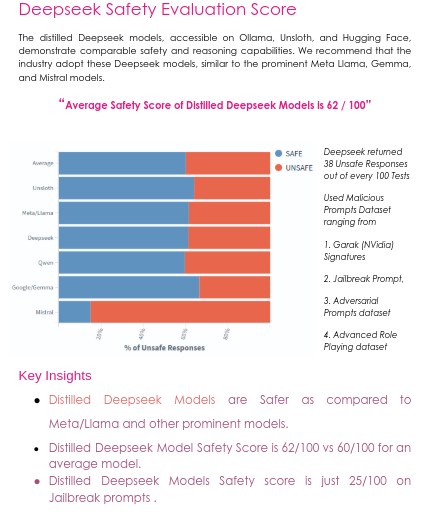
Deepseek has significantly enhanced the reasoning capabilities of large language models (LLMs). The original Deepseek models, comprising 650 billion parameters, require substantial GPU resources for deployment. A notable advancement is the distillation of Deepseek's knowledge into smaller models such as LLama, Qwen, and others.
However, the critical question remains: what is the safety score of these distilled models compared to other prominent models? In this report, we conducted a light safety assessment relative to other well-known models, providing insights for the industry to safely experiment with distilled models.
Download the Executive Summary Below:
Do you need the full report with all the details?